Relationship with Other Techniques to Improve LLM-powered Systems
Since agents make up for the limitations of LLMs, one might wonder if they are replacements for other techniques to improve LLMs performance. In most cases, they are not substitutes, but rather, complementary approaches that can be integrated into an agentic system.
Retrieval Augmented Generation (RAG)
RAG is one of the most popular approaches to ground LLMs in domain-specific knowledge. By retrieving relevant documents from internal knowledge bases and including them in-context, LLMs are able to accurately answer questions beyond their innate knowledge.
Agents are related to RAG in at least two ways:
- RAG can be used as a tool by an agent to retrieve knowledge. For example, a research agent could access an internal knowledge base via a RAG tool to retrieve relevant documents for its research task.
- RAG workflows can be augmented with agentic capabilities. In a standard RAG workflow, relevant documents are retrieved from the knowledge base and synthesised by the LLM to obtain the final answer in a single pass. In an agentic RAG system, the query may run in a loop, where the RAG system is iteratively queried until sufficient information has been gathered to meet the objective. In addition, other tools like web searches could be incorporated.
Fine-tuning
Fine-tuning is another way to ground LLMs in knowledge beyond their pre-training corpus. In contrast to the RAG approach of retrieving relevant documents to use in-context, fine-tuning (and continual pre-training) can be performed to “insert” new knowledge into the LLM.
LLMs can also be fine-tuned specifically for agentic systems - just as we can fine-tune LLMs to follow instructions, we can do the same to improve planning and reasoning abilities, or the ability to interact with specific tools and APIs. For example, Toolformer fine-tuned GPT-J to learn specific tools, while Song et al fine-tuned Llama 2 on the AgentBank dataset to get Samoyed, an LLM agent which is capable of executing multi-step tasks.
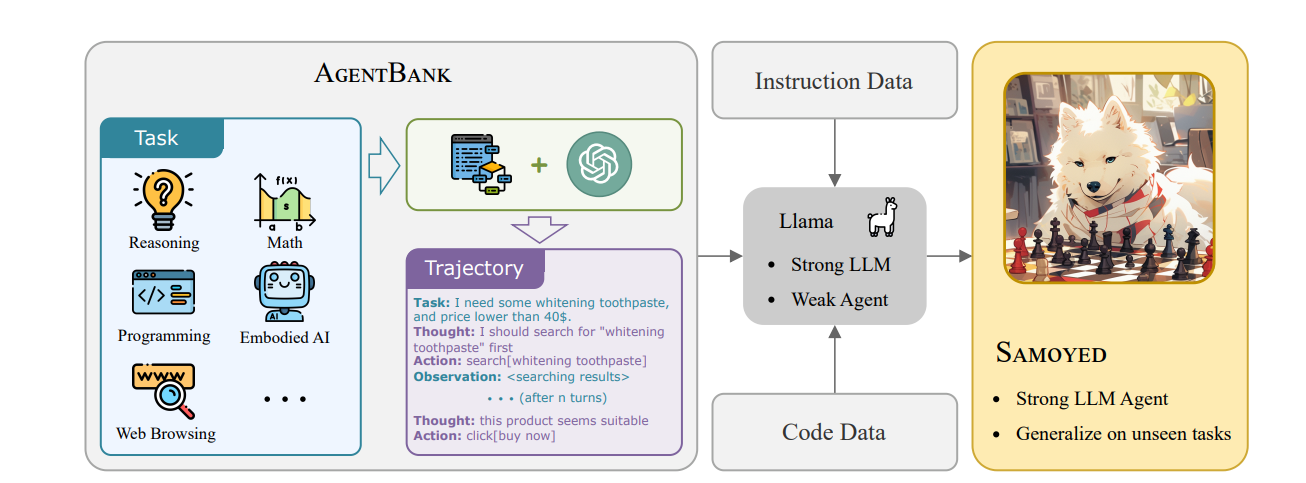
Fine-tuning the Samoyed LLM Agent from Llama 2
Image source: https://arxiv.org/pdf/2410.07706
Fine-tuning LLMs for planning and reasoning is similar to fine-tuning them to follow instructions. In instruction tuning, we fine-tune LLMs on instruction-response pairs to get them to learn how to respond to different instructions. Fine-tuning LLMs to have agentic capabilities extends this by replacing instruction-response pairs with a series of thoughts and observations. Instead of learning how to carry out an instruction, the LLM has to learn how to “think” through problems, break it down into steps, observe the user’s response and react dynamically to achieve the overall objective.
TL;DR
Agentic AI complements other techniques to improve LLM-powered apps like RAG and fine-tuning, instead of replacing them.