Testing
Key Message
Testing is the process of establishing risk categories of interest, creating benchmarks and establishing quantitative metrics, and measuring a system's performance against the benchmark. Testing should be (i) meaningful and representative, (ii) contextualised, and (iii) continuous.
What is testing?
Testing (possibly also known as "evaluations") is the process of
- establishing risk categories of interest
- creating and defining benchmarks
- measuring a system's performance against this benchmark
in order to ensure that the system is accurate, reliable and robust.
 Figure: Stages of testing maturity in AI systems.
Figure: Stages of testing maturity in AI systems.
We can think of testing maturity in stages. Ideally, we want to be at level 4, where testing is comprehensive and automated. At level 4, testing is continuously performed, ensuring that risks are continuously monitored and mitigated as users interact with the application and data distributions shift. However, based on our knowledge, level 1-level 3 testing are most commonly adopted in the industry today. This is largely due to the difficulty in measuring how good/trusted/comprehensive the testing benchmark is. Nonetheless, as SOTA moves towards level 4, we believe that we can gradually level up Whole-of-Government (WOG) testing of AI systems.
Principles for Effective Testing 🎯
We have four guiding principles when collecting data for testing:
- Meaningful and representative: Testing needs to be meaningful by ensuring that data need to accurately and directly test the LLM for risk of concern. Testing needs to be representative and accurately reflect the real-world distribution of risks that users may encounter. For example, a human-facing application needs to be tested with data that is sufficiently realistic and naturalistic.
- Diverse and varied: Testing needs to be diverse in content, framing and sources to ensure comprehensiveness. They must cover a broad range of risks (i.e., content) and vary in linguistic structure, in order to reflect the real-world distribution.
- Contextualised and/or localised: Testing needs to be localised to the context. If we're testing for toxicity in Singapore, this includes Singapore-specific references, vocabulary, and grammar. Curating long-tail, context-specific tests is valuable in assessing whether the model can detect underrepresented forms of localised risks.
- Incremental complexity: The design of attack levels should align with the target users, starting with simple adversarial tests and gradually increasing in sophistication. Intermediate attacks combine basic level prompts with adversarial prompting templates like role-playing exploits and prompt injections to enhance difficulty.
Key testing dimensions
Safety Testing 🦺
Safety testing is crucial for generative AI applications because their stochastic nature can produce unpredictable and potentially harmful outputs. Ensuring these systems operate within safe boundaries helps mitigate safety risks in WOG AI applications.
See safety testing for more details.
Fairness Testing ⚖️
While outputs are constrained and more predictable in discriminative AI applications, they can nonetheless disproportionately impact certain groups based on protected and sensitive attributes like race or gender. Hence, significant work has been done to establish fairness testing and metrics in discriminative AI.
See discriminative AI fairness testing for more details.
Similarly, fairness testing is essential in generative AI to ensure that outputs do not perpetuate biases or discriminate against specific groups. This is especially due to the fact that LLMs have been trained on Internet data, which are known to contain biases.
See generative AI fairness testing for more details.
Robustness Testing 💪
Robustness refers to a system’s ability to maintain reliable performance when faced with unexpected or challenging conditions, like noisy inputs, adversarial attacks, or shifts in the environment. It is important for AI applications to behave consistently well on unseen, perturbed, or out-of-distribution examples. Robustness is critical for any AI system deployed in high-stakes settings, especially in government services, where citizens depend on accurate, up-to-date information to make decisions with financial, legal, or medical consequences.
See robustness testing for details.
Agentic Testing 🤖
Agentic systems are often more prone to unsafe behaviors than their base models, partly due to their growing autonomy and expanded capabilities through tool integration. As agentic systems are able to define their own goals and plans and execute multi-step operations without humans in the loop, the impact and blast radius of failures in agentic systems are significantly larger. Instead of simply testing the outputs of the AI application, we need to test and evaluate the safety, security and robustness of each component in the agentic system.
See agentic testing for details.
Responsible AI Benchmark
We have developed the Responsible AI Benchmark, a collection of application-level safety, robustness and fairness tests designed around real-world use cases. The benchmark serves as a rough guide for developers in filtering down a subset of appropriate models for their use case. However, it is still necessary for application developers to conduct their own testing before deployment.
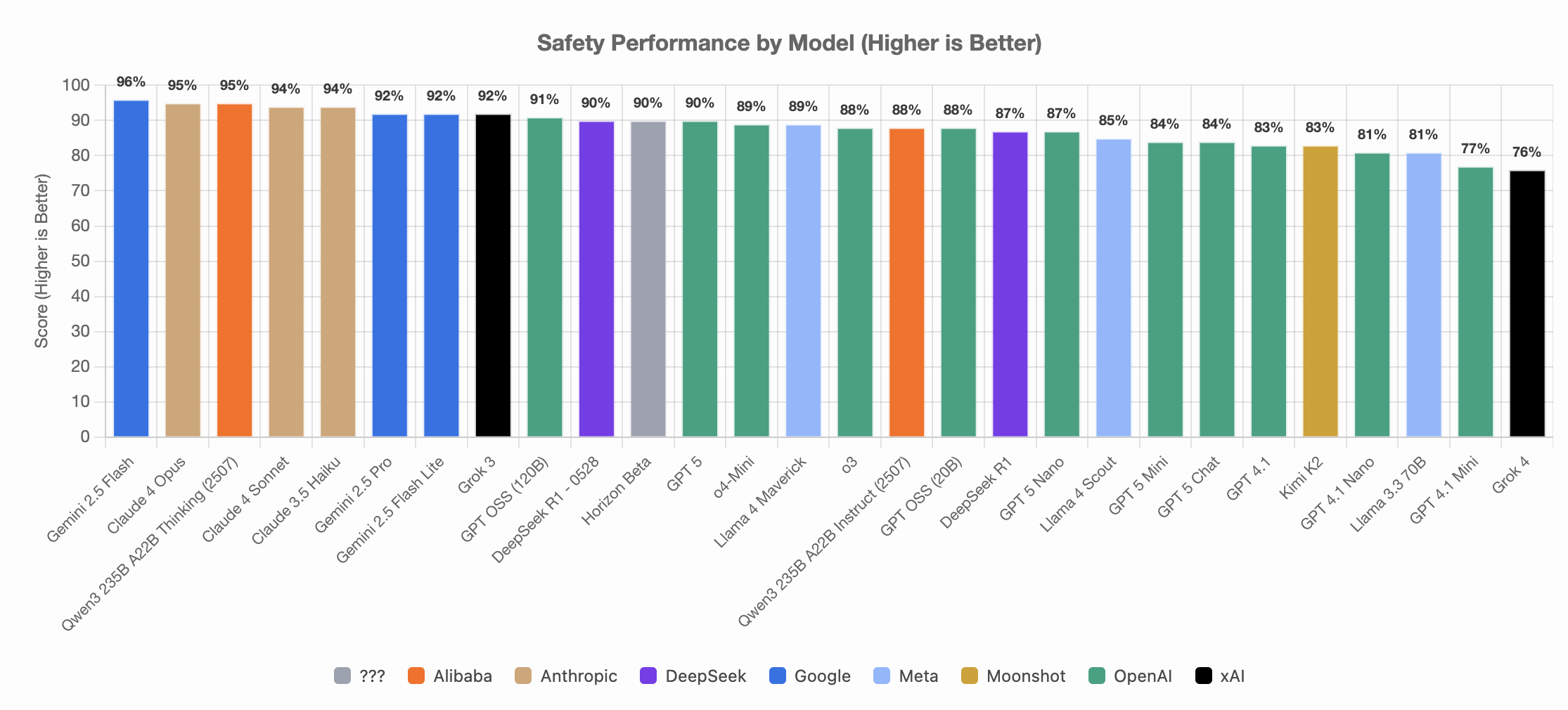
Screenshot of RAI Bench on Safety Performance, taken on 12 Aug 2025
Visit the Responsible AI Benchmark space for updated results and information.
Creating Your Own Benchmark
The process for generating your own dataset for testing may look something like:

Testing flow and process.
What is most important is that the process of testing is iterative, and almost a continual "cat-and-mouse" game as testing data is used to train defences, which generate labels that can be used for generating even more testing data. If possible, production data can also be randomly sampled and used for benchmarking.
Human Evaluation
To create your own benchmark, you can rely on LLMs to generate synthetic data at scale, as well as humans to ensure alignment and accuracy. To generate representative and large-scale datasets, humans realistically cannot write and annotate all data. Instead, humans can typically annotate a subset of data, which is then used to evaluate the LLM evaluators.
Alternative Annotator Test (Alt-Test)
The Alt-Test is one way to conduct robust evaluation of your LLM-as-a-judge. It reframes the goal of evaluation from "Is the model correct?" to "To what extent to LLMs concur with human annotations?"
Essentially, it is a leave-one-annotator-out hypothesis test that measures whether an LLM judge agrees with the remaining human consensus at least as well as the left-out human does.
How is this better than traditional metrics? Commonly used agreement measures (e.g. Cohen's kappa, Krippendorff) only assess agreement among annotators, and performance metrics (e.g. Accuracy, F1 Score) only evaluate whether the LLM matches human performance. The Alt-Test provides two key advantages: - It is actionable: a high winning rate provides statistical evidence that the model can stand in for human annotators, and the advantage probability provides a measure to compare between models. - It captures the variability amongst humans themselves, accounting for the fact that humans disagree with each other.
The Test in Action
An hands-on implementation and extension of the Alt-Test can be found in this blog post.
For more details, see the original Alt-Test paper.