Chapter 2: Stages of MLOps
If you’ve worked on developing or using ML models, you’re familiar with the challenges of constantly updating data, adjusting models, and managing feedback loops.
Many assume that implementing MLOps is burdensome and complex, but this perception often stems from uncertainty about where to begin. MLOps is designed to scale your existing data science operations efficiently and reliably, allowing for fast creation of new use cases and enabling long-term deployment of ML model. Here’s what you can expect from adopting MLOps processes:
- Faster model development and update: MLOps frees up time for teams to take on more development work, allowing data scientists to focus on the scientific aspects of their work.
- Coordination: It fosters self-managed teams, leading to shorter time-to-market and better collaboration between IT, research, and end-users.
- Reliable ML Systems: MLOps enables the development of systems with higher performance, scalability, and security.
In this chapter, we’ll outline the stages to bridge the gap in MLOps knowledge. In each of these stages, we recommend gradually developing MLOps capabilities, prioritizing the areas most relevant or easiest to implement for your agency, instead of trying to develop everything defined in a certain stage at one go.
There are several useful references that outline the stages of maturity in the MLOps journey. One such example is Microsoft’s MLOps Maturity Model. The Microsoft MLOps Maturity Model is a straightforward and widely recognized framework that highlights key principles and practices for advancing machine learning systems. It is grounded in a software engineering-oriented approach.
In our approach, we take a slightly different stand, and define three stages of MLOps maturity that agencies can use as a reference. These stages provide a step-by-step pathway, beginning with a small team of data scientists and gradually building towards a more mature and operationalized setup.
2.1. Stage 0: Manual Process
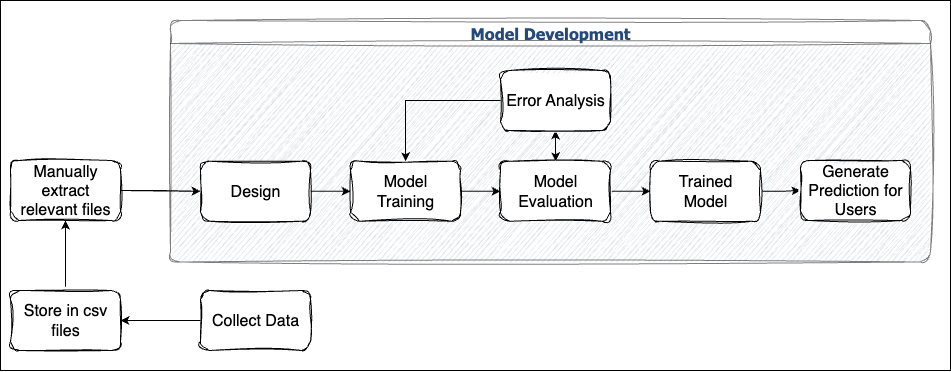
Some agencies remain at this stage because it meets all their needs. Most of the time, their models are developed for one-time use or they rely on model inference & descriptive statistics to narrate data stories and make decisions. Occasionally, they are manually retrained when performance issues are identified. With each new dataset, the team reassesses the data, makes necessary adjustments, and updates their presentations.
This stage corresponds to Microsoft’s MLOps Maturity Model Level 0, and typically have the following attributes:
People: Data analysts and scientists primarily engage in exploratory data analysis (EDA) and model development, often with limited understanding of data or software engineering roles. Their focus is on deriving insights from data and fine-tuning predictive models.
Process: ML development lacks proper documentation or version control, making reproducibility difficult. Data pipelines are often dependent on third-party systems or ad-hoc setups.
Technology: ML development usually takes place on local machines or the MAESTRO platform (formerly known as Analytics.gov, AG@GCC), using tools like RStudio or Jupyter Notebook, and SQL for direct database queries.
2.2. Stage 1: Basic Automation

In this phase, most processes remain manual, though a functional model is developed with some version control and documentation, typically stored on platforms like GitLab. For example, data scientists may upload their code to GitLab, but a CI/CD pipeline is often either minimal or nonexistent. At this stage, the focus is on delivering predictions or dashboards to customers, allowing users to interact with the outputs independently. For instance:
- Amazon SageMaker Endpoints might be used to serve model predictions.
- Predictions can be visualized on front-end platforms like Tableau dashboards or Streamlit applications hosted via CStack.
This stage corresponds to Microsoft’s MLOps Maturity Model Level 1, and typically have the following attributes:
People: Data scientists begin facing challenges in implementing prediction services and mastering version control, pushing them to develop more engineering skills. Organisations with established engineering teams make this transition more smoothly, while those lacking in such resources may experience delays. Data scientists are skilled at understanding model functionality and predictions, but often lack expertise in model monitoring and updating.
Process: Most processes remain manual, though some automation is introduced — typically by creating a prediction service with a front-end interface for user interaction. Model releases are infrequent, and while data scientists produce artifacts like trained models and evaluation metrics, continuous performance monitoring is often neglected. Model updates are introduced via unstructured manual processes.
Technology: ML deployment tools offering endpoint services (e.g., SageMaker) paired with front-end platforms (e.g., Streamlit, Reflex) play a crucial role in deployment. These tools provide the infrastructure for hosting and serving models to end-users or applications.
If this sounds relevant to you, proceed to Chapter 3 for a detailed technical walkthrough of transitioning from Stage 0 to Stage 1 using MAESTRO AWS SageMaker.
2.3. Stage 2: Automated Pipeline

If you haven’t started a prediction service and would like to learn how as soon as possible, stop here and head to Chapter 3. Otherwise, please continue reading.
This stage includes multiple components and can be challenging for many agencies as they start implementing MLOps. It touches on various areas with advanced capabilities. In Stage 2, the focus will be one ensuring all the essential components are in place.
We recommend conducting a broad assessment of these areas, prioritizing some while progressing more gradually in others. We understand this won’t be straightforward, so we’ll dive much deeper in Chapter 4, where we’ll provide a starting point how to build the necessary team and infrastructure.
For now, let’s start with a brief overview of the operating model.
People : At this stage, the initiative is viewed as creating a data product or platform. The role of data scientists has expanded significantly, prompting agencies to start forming teams dedicated to different aspects of MLOps. Possible team structures might include:
- Core
-
Data Science Team: Science Lead, Data Scientist, ML Engineer, Data Engineer
-
Partner Teams
- DevOps & Data Engineering Team: Tech Lead, DevOps Engineer, Data Engineer
- Infra & Security Team: Agency Adminstrator, CISO, Business Analyst
- Business Team: Business Lead, Project Sponsor
- Product/Front-end Development Team: Product Manager, Project Manager, UX/UI Designer, Software Engineer
Processes & Technology: In this stage, the data science team should expand to at least 2–4 members, or more depending on the use case. They will collaborate with other teams and oversee three key MLOps processes:
- Data Pipeline
Data engineers will set up the necessary ETL processes and automate the flow of high-quality data from various sources to ensure it's ready for machine learning model development and deployment. - Key artifacts: Data pipelines, feature stores, and data validation scripts.
-
ML Engineering
DevOps engineers will maintain and optimize the CI/CD pipeline, ensuring smooth automation and operations. They are also responsible for infrastructure management and maintaining the prediction service. -
Key artifacts: Release strategy, model registry, source repository, prediction service.
-
Science
This area focuses on scaling machine learning development for MLOps purposes. It usually takes a backseat until the pipeline and infrastructure are running smoothly. - Key artifacts: Experiment tracking, trigger conditions, continuous monitoring scripts, model evaluation and validation scripts, feedback loop strategy, and manual/automated re-training processes.
We'll cover more details on these processes & tools from Chapter 4 onwards.
2.4. Stage 3: Full MLOps
While Stage 2 is focused on establishing all essential MLOps components, Stage 3 is about customizing the setup to meet specific agency requirements, such as configuring environments for more sensitive data classifications, advancing automation and quality improvements in the MLOps process. Since the precise needs will differ between agencies, we advice you to using the AI Practice 10-Category Needs Framework in Chapter 7 to accurately discern and cater to your MLOps requirements.
2.5. References
Practitioners guide to MLOps: A framework for continuous delivery and automation of machine learning, Google, 2021 https://cloud.google.com/resources/mlops-whitepaper?hl=en
Designing Machine Learning Systems, Chip Huyen, O'Reilly', 2022
MLOps Principles, INNOQ, https://ml-ops.org/content/mlops-principles
https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning https://www.coursera.org/learn/introduction-to-machine-learning-in-production